
The rise and rise of GPUs
While today’s silicon technology is highly optimised for fast calculations, demand for faster processing speed is increasing. Over the past two decades, microprocessor clock rates (the frequency at which a microprocessor runs instructions) have spiralled up into the gigahertz, but memory has failed to keep up. The graphics processing unit (GPU), a device that evolved alongside the microprocessor, has helped provide an answer to this problem.
Modern GPUs are very efficient at manipulating computer graphics and image processing, and their highly parallel structure makes them more effective than general-purpose central processing units for algorithms where processing of large blocks of data is done in parallel. They are beginning to reshape the way computers are designed and programmed, whether they are used inside cars, mobile phones or supercomputers.
Improving graphics
In the 1990s, the computational load required to render new 3D games, such as Quake, drove a transfer of technology originally used for displaying graphics for flight simulators into the PC. Conventional microprocessors, such as those made for PCs, are designed to run as wide a variety of software as possible. Such flexibility calls for a design that is balanced between the ability to fetch pieces of data, perform calculations on them and make decisions on the results. However, the process of fetching data from memory introduces delays and slow performance. Not only does the microprocessor have to wait for the data before it can work on it, but each decision may also take the program down a different branch of code that calls for a new stream of instructions and data not in the caches. While this happens, the instruction pipeline – the ‘assembly line’ of dependent tasks to be executed in order – has to stall and wait – see Pipelines and bubbles.
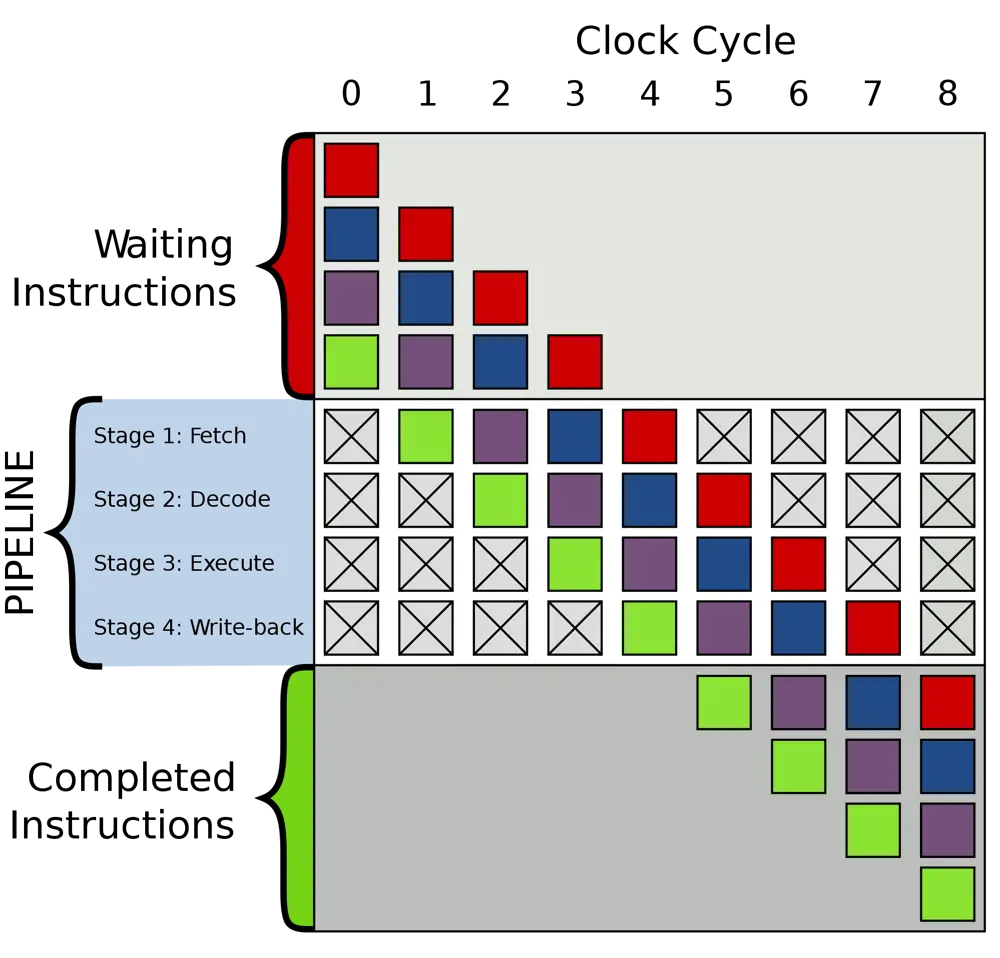
Generic 4-stage pipeline; the coloured boxes represent instructions independent of each other © Wikimedia Commonss
Pipelines and bubbles
To allow it to perform work as quickly as possible, a central processing unit overlaps the instructions it works on in the form of a pipeline. The most basic pipeline sequence is the four-stage ‘Fetch, Decode, Execute and Writeback.’ However, some steps of the pipeline may take longer to complete than others, or may need to wait for other instructions to complete and return results.
Bubbles form in the pipeline when an operation has to stall. Instructions further ahead in the pipeline will be able to complete, but those behind the stalled instruction have to wait. Very often, this is because of a fetch from memory. Writes to memory do not stall in the same way because most processors allow instructions to complete out of order. Because the processor does not need to know the result of the write, only that it happened, a stall will only occur if the processor finds it has to read the value from memory.
GPUs attempt to remove pipeline bubbles through a combination of multi-threading and making data available earlier through the use of faster local memory.
Because of the kind of work it has to do, a typical 3D graphics rendering task has little need for branches and some of the other features of a standard microprocessor, and the GPU structures operations to hide the long latency of memory - see Inside the GPU.

Pipeline bubble. If an operation to add two numbers together follows the instructions that load them from memory into registers, the pipeline may have to stall to wait for the data to arrive. This introduces a bubble that delays completion of the addition
The parallel array provides a massive increase in speed over trying to do the same operations on the main microprocessor
Data elements do not depend on feedback from each other, so it becomes possible to split the arithmetic over an array of computational units – as many as can be economically squeezed onto an integrated circuit. The parallel array provides a massive increase in speed over trying to do the same operations on the main microprocessor.
As a result, whereas one of today’s microprocessors might be expected to perform 60 billion multiplications per second, a GPU that has hundreds of arithmetic units working in parallel on 3D images can sustain more than 600 billion. Early GPUs, such as those made by PC graphics pioneer 3Dfx, saved precious silicon area by limiting their programmability. Because the algorithms they ran were so predictable, they could be rendered into hardware and could remove the complex control circuitry that characterises microprocessors. However, this limited the amount of realism that was possible to achieve on a PC.
At about the same time, movies created by Pixar’s Renderman such as Toy Story demonstrated how powerful computergenerated graphics could be. But performance would have to improve to deliver those images in real time. It took up to 15 hours to render a single frame of Toy Story, even with the workload divided across 100 computers. Renderman ran entirely on conventional microprocessors because the animation company needed the flexibility they offered to incorporate specialised software to handle eyes, hair and other problematic objects to which algorithms originally used for flight and scientific simulations paid no attention. Moore’s Law – the observation that the number of transistors in a dense integrated circuit doubles approximately every two years - provided the impetus for programmability in PC graphics. Each doubling in transistor density could almost double the amount of compute power available by adding more and more parallel processors.
It took up to 15 hours to render a single frame of Toy Story, even with the workload divided across 100 computers
Although the programmability would be far more restricted than what was available to Pixar, Microsoft decided at the end of the 1990s that it would put support for modifiable rendering engines – called ‘shaders’ by Pixar – into the Direct3D software the company created for its Windows operating system. Graphics standards body Khronos Group followed with the OpenGL library, which made it possible to write games and other 3D software to one standard and have it run on any combination of operating system and GPU that supports the standard.
The PC was only one recipient of the technology. UK-based Imagination Technologies’ novel approach to rendering lent itself to implementation in mobilephone chipsets, which demanded much lower power consumption than was possible with the other GPU architectures. Imagination has the most commonly used GPU inside mobile phones and other consumer electronics devices. By mid-2013, its technology lay inside some five billion products and could be found in close to 38% of mobile-device chips with embedded GPUs.

The Soft Kitty video demonstration for the PowerVR series of GPUs shows how polygons are used to create the underlying frame for a series of rendering stages that are completed with a realistic layer of fur © Imagination Technology
Inside the GPU
The modern graphics processor unit (GPU) is at its heart an array of computational engines. Each of those engines is dedicated to performing a subset of the operations that a conventional microprocessor can handle, allowing them to be optimized for their specific tasks.
Some of the engines will run software. Others are implemented as almost pure hardware circuitry because this increases power efficiency. A hardware circuit can be more efficient not just because it has less control-logic overhead but because it does not have to fetch commands from memory to determine what to do at each step. The energy of a fetch from memory can be ten times more than that of a mathematical calculation, so the power savings are significant.
Similarly, because the same operations will apply to a series of matrix multiplications, it is possible to use the same program to drive an array of processing units in parallel. The same instruction is performed at the same time across four, eight, sixteen or more units in a group. This single-instruction, multiple-data (SIMD) architecture simplifies the hardware design of the GPU without sacrificing performance for these types of operation.
As memory latency is a key problem for computers, GPU designers work around this in two ways. One is to fetch the data well before it is required and only set the array of shaders into action once it is stored in a fast, local area. The second is to employ a technique called simultaneous multi-threading (SIMT) as even the local memory can incur a latency of several clock cycles. In a SIMT architecture, the processing units quickly swap between instructions from different streams or threads. Typically, a thread will first load data to work on but, while that data is being fetched, swap to an instruction from another thread that, if scheduled correctly, has the data waiting for it. By the time the processor returns to the first thread, its data will be ready to process.
Like UK company ARM, which has a GPU share of 25% of smartphones, Imagination licences its technology to chipmakers such as Intel and Samsung, as well as Apple, which has devices made for its iPhone by Samsung and TSMC.
Many applications that need high computing performance perform large numbers of matrix multiplications, and so were suited to being run on the GPU

The GPU has become an increasingly important part of mobile processors. Images taken by technology-analysis firm Chipworks show that the Apple A6 and its successors devote at least as much die area to the GPU– designed by Imagination Technologies – as to its CPUs © Chipworks
When software made it possible to decide what would be processed on the GPU’s arithmetic engines, programmers began to exploit their computational power. Many applications that need high computing performance perform large numbers of matrix multiplications, and so were suited to being run on the GPU. Developers found ways to use OpenGL to perform these calculations on the GPU and, instead of rendering the results from the screen, pulled them back from the device.
In 2008, ARM CTO Mike Muller coined the term ‘dark silicon’ to describe a looming problem for chipmakers for mobile products: the number of logic transistors that can be packed onto a chip is growing so large that even if there were enough available power from the battery to run them, the device would most likely overheat. One answer is to use those additional transistors to build highly specialised processors that could run instead of software on a microprocessor. One of those is likely to be the GPU, which takes up more silicon area than the processors that feed it commands.
Despite their computing power, GPUs do not always result in a dramatic improvement in performance even in applications where the software writers have the resources to tune their code to run well on the processors. Some high-performance computing users have employed devices that allow the logic circuits inside them to be rewired dynamically. London-based Maxeler Technologies has supplied hardware to customers such as JP Morgan for high-speed financial analytics, and the Daresbury Laboratory for a range of scientific computing problems. The Daresbury ‘dataflow’ supercomputer will have a predicted performance per watt that tops the 2013 Green 500 list of most energy-efficient high-performance machines.
New uses
GPUs are beginning to sit alongside products that are intended to process incoming images for applications such as computational photography and augmented reality. These applications call for the ability to identify and track objects in a scene, in real time. Low latency is important to virtual and augmented reality applications because, for users to avoid motion sickness, the time the applications take to respond to movement has to be below 10ms. To increase their flexibility, GPUs are acquiring features, such as the ability to handle branches, although this support reduces the data throughput of the architecture.
Low latency is important to virtual and augmented reality applications because, for users to avoid motion sickness, the time the applications take to respond to movement has to be below 10ms
The combination of graphics and visual processing is moving outside consumer products and into areas such as the development of safer cars. Vehicle manufacturers are using the devices to develop advanced driver assistance systems that survey the environment to detect hazards and either warn the driver or allow the electronics to take direct action such as applying the brakes. Similar systems could help the visually impaired navigate the world around them, using the visual processing engines to identify objects and tell the user about them or provide tactile warnings.
To save power, the algorithms used on these devices will start to move between the different computational engines available on a chip. ARM is developing software that allows a management application to track the power usage of code and restart a different version on a GPU or microprocessor if it thinks it will be more efficient at that time. For example, if a task would push a microprocessor onto a much higher clock rate and the GPU has spare capacity that allows it to run in a more energy-efficient mode, the GPU version is the one that will be allowed to run. To help spread the use of this approach, ARM decided to contribute the code to Linux so that the operating system could be tuned to handle the requirements of heterogeneous computing as power becomes a primary concern for system designers and programmers.
the next 15 will likely see the GPU absorbed into a broader heterogeneous computer architecture in response to the new power crisis
If the past 15 years have seen the GPU rise in importance because of power problems on the microprocessor, the next 15 will likely see the GPU absorbed into a broader heterogeneous computer architecture in response to the new power crisis.
Enter the matrix
The graphics pipeline is the core of most approaches to 3D rendering. Originally performed entirely by dedicated hardware but now the focus of the graphics processing unit (GPU), the graphics pipeline offloads almost all the work of rendering a scene from a host microprocessor to the point that all it needs is a description of the world it is meant to display and the position of the observer. The microprocessor feeds the GPU the coordinates of a series of triangles that represent all the shapes in the virtual world that the software is programmed to show.
Through a series of matrix multiplications, the GPU then computes how this collection of triangles should look to an observer at a position set by the software. As the observer moves around the world, the matrices used to effect the transformations change – changing the view of what is at this stage a simple wireframe model. It is a technique that has remained in place since leading computer scientist Ivan Sutherland performed early experiments into virtual reality in the late 1960s.
The next step is to ‘rasterise’ the image. GPU routines use the pixel colour set for each vertex to interpolate the colour for the pixels that lie inside each triangle. If this were the last step, it would result in a blocky but effective 3D image. One or more shader programs add the level of realism to which gamers and other users have become accustomed.
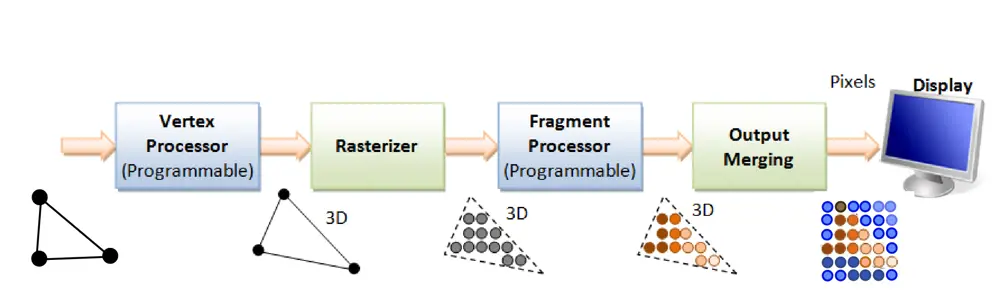
The graphics pipeline used by GPUs splits the rendering of 3D images into a series of stages that begin with the projection of simple triangles onto a 2D surface, followed by stages that convert the vector representation into pixels that are lit and textured before being merged into a final sea of pixels sent to the display
Shaders can be used to smooth surfaces using more advanced algorithms that hide the edges of triangles and apply textures, bumps and reflections to the surface to make them resemble real-world objects. In recent years, GPU manufacturers have created more functions that can be added to the instruction pipeline. A major change occurred with the introduction of geometry shaders that can take a single shape and apply it across a surface. This can be used to create hair or fur from a single template image and apply it to a character’s head.
Chipmakers have, from time to time, attempted to move the industry over to techniques that are radically different to the graphics pipeline such as ray-tracing. Intel designed a GPU codenamed Larrabee around the technique. But the chip giant found its performance was insufficient to compete with existing products so steered the technology into the Xeon Phi coprocessor for supercomputers, where the parallel processors on the chip could be used for scientific code. But interest in ray-tracing has resurfaced because it can handle some visual effects that are hard to achieve using the conventional graphics pipeline.
As part of a hybrid rendering architecture, ray-tracing can add additional levels of realism that are difficult to achieve by shader programs. Imagination Technologies is building a hardware ray-tracer into its PowerVR 6 products to give software the ability to apply the techniques to key parts of the frame to provide more realistic shadows, reflections and refractions. ARM’s global illumination solution is the Geomerics Enlighten engine.
***
For this article the author talked to AMD, ARM, Imagination Technologies, Intel, nVidia, Maxeler Technologies, Stanford University and PTR Group.
This article has been adapted from "The rise and rise of GPUs", which originally appeared in the print edition of Ingenia 61 (December 2014).
Contributors
Chris Edwards
Author
Keep up-to-date with Ingenia for free
SubscribeRelated content
Software & computer science

Pushing the barriers to model complex processes
In 2007, Imperial College London spinout Process Systems Enterprise Ltd won the MacRobert Award for its gPROMS (general-purpose PROcess Modelling System) software. Costas Pantelides and Mark Matzopoulos, two of the key people behind the success of gPROMS, tell how they created a way in which engineers can harness physics, chemistry and engineering knowledge within a framework that solves highly complex mathematical problems.

Compact atomic clocks
Over the last five decades, the passage of time has been defined by room-sized atomic clocks that are now stable to one second in 100 million years. Experts from the Time and Frequency Group and the past president of the Institute of Physics describe a new generation of miniature atomic clocks that promise the next revolution in timekeeping.

EU clarifies the European parameters of data protection
The European Union’s General Data Protection Regulation, due for adoption this year, is intended to harmonise data protection laws across the EU. What are the engineering implications and legal ramifications of the new regulatory regime?

Evolving the internet
He may have given the world the technology that speeded up the internet, but in his next move, Professor Nick McKeown FREng plans to replace those networks he helped create.
Other content from Ingenia
Quick read

- Environment & sustainability
- Opinion
A young engineer’s perspective on the good, the bad and the ugly of COP27

- Environment & sustainability
- Issue 95
How do we pay for net zero technologies?
Quick read

- Transport
- Mechanical
- How I got here
Electrifying trains and STEMAZING outreach

- Civil & structural
- Environment & sustainability
- Issue 95